Database Normalization Forms and all that Jazz

Personal introduction to RDBMS Normalization Forms with a taste of Formula 1
Published on July 18, 2024 by Erik Pillon
article post review
6 min READ
While developing software, is difficult not to acknowledge the central role that data (and databases in general) play in the overall architectural design of the system. Now more than ever, in the era of Big Data, data-intensive applications, and Data Lakes, this principle remains a cornerstone for every developer willing to design any type of application or software. It is therefore fundamental to create and organize data in a way that preserves integrity and avoids redundancy, allowing scalability and efficiency.
In Relational Databases, these principles go under the name of normalization forms, i.e., a set of principles and best practices that prevent data redundancy, operational anomalies, and inconsistency through systematic and standardized techniques governing database relationships and dependencies.
Normalization forms build upon each other in progressive steps, meaning that a database cannot be in a, let’s say, 3rd normalization form without being first in the 2nd normalization form.
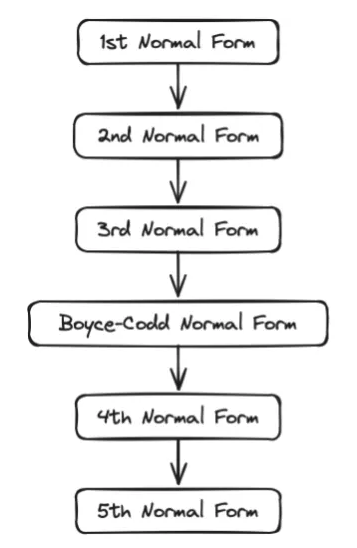
While the schema above shows only until the 5th normalization form, it must be noted that the diagram could extend even beyond, but quite often all normalization forms that go beyond the 3rd normalization forms don’t offer any practical utility and are mostly interesting for academic purposes only.
First Normalization Form
1st Normalization Form (1NF) is about the atomicity of the entries and their unique identification. This eliminates repeating groups and ensures each field contains only one piece of information. 1NF is essentially telling us how (not to) use the principal keys (PK) in our database.
Let’s consider the case in which we have a table of Formula 1 drivers and their teams. A non-optimal usage of the unique key can lead to the following mispractice: a driver drives in the year X for a team, but the team can change with time. Specifying only the DriverId is therefore not enough for accessing the Team property.
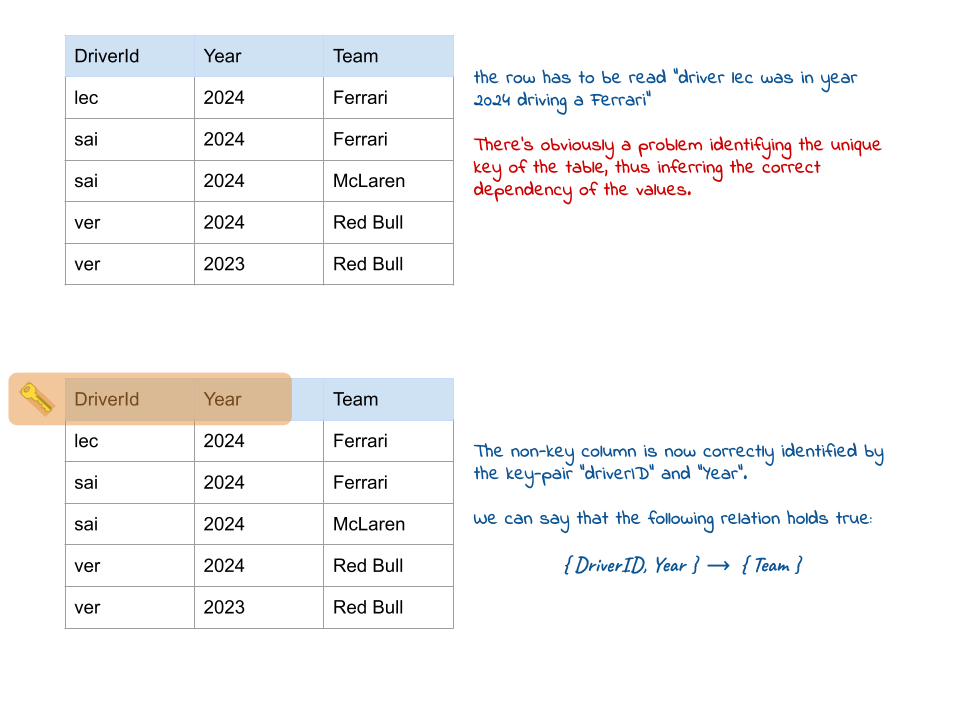
We would like essentially to hold true the following
’’’ { DriverId } -> { Team } ‘’’
but unfortunately is not the case (a driver can be driving a Ferrari in 2024 and a McLaren in 2022). The solution to this problem is the redefinition of the unique key constraint (in this case DriverId AND Year).
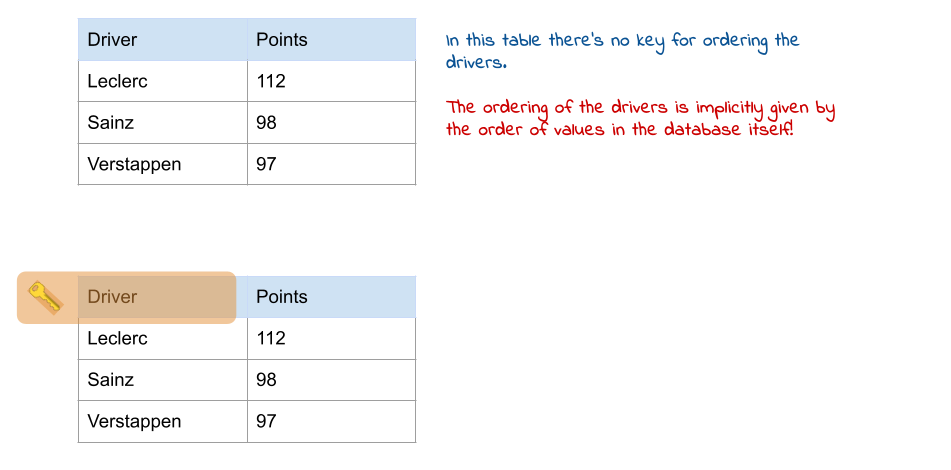
Let’s consider now a second scenario, where the order in which data are presented yields secondary information about the drivers. In the following table, we see that the order in which the drivers are stored is implicitly ordered already by their championship ranking. This cannot happen and must always be fixed by simply defining a principal key in the table.
Second Normalization Form
2nd Normalization Form builds on 1NF by ensuring that all non-key attributes are fully functionally dependent on the primary key. This means that there are no partial dependencies of any column on the primary key, eliminating redundancy.
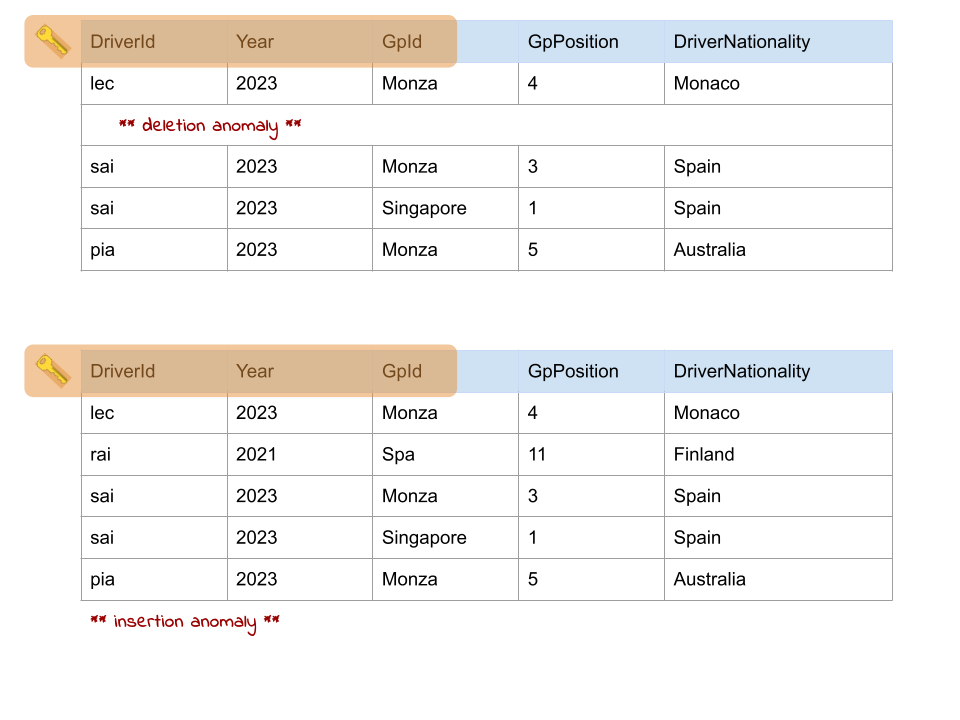
Let’s consider the following case where we have in the same column information about the driver’s GP result of a given year and also information about the nationality of the driver. Driver nationality has indeed an explicit dependency on the Driver ID but has nothing to do with the GP in which the race was held. This creates a problem in case there’s a so-called insertion anomaly or deletion anomaly of an entry, allowing the possibility of a data inconsistency!
Third Normal Form
3rd Normal Form (3NF) requires that all the attributes are not only fully dependent on the primary key but also non-transitively dependent. This means there are no transitive dependencies, where non-key attributes depend on other non-key attributes.
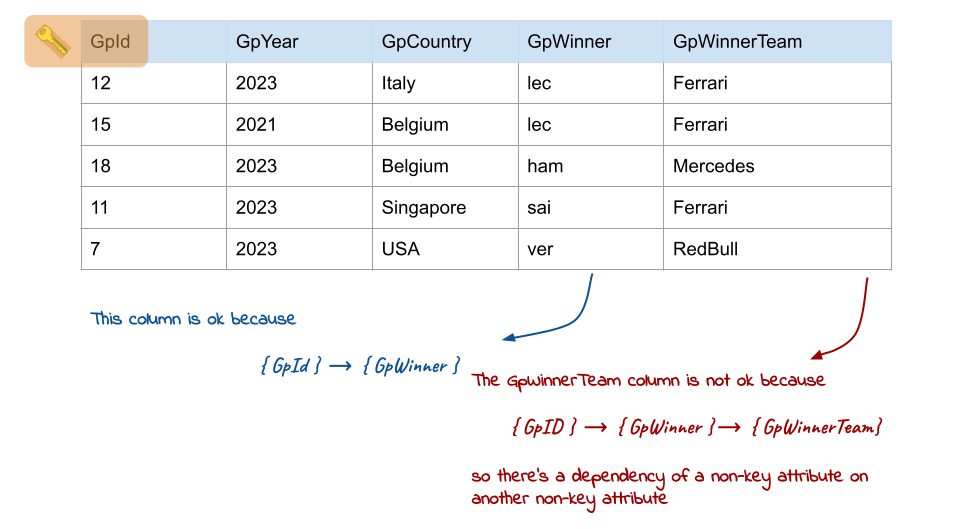
The problem, in this case, is that the last column (GPWinnerTeam) has an evident dependency on the column (GpWinner), creating the risk of data inconsistency in case of insertion or deletion anomaly. The above-mentioned problem can be fixed by simply splitting the two tables into their respective data structures, like in the following:
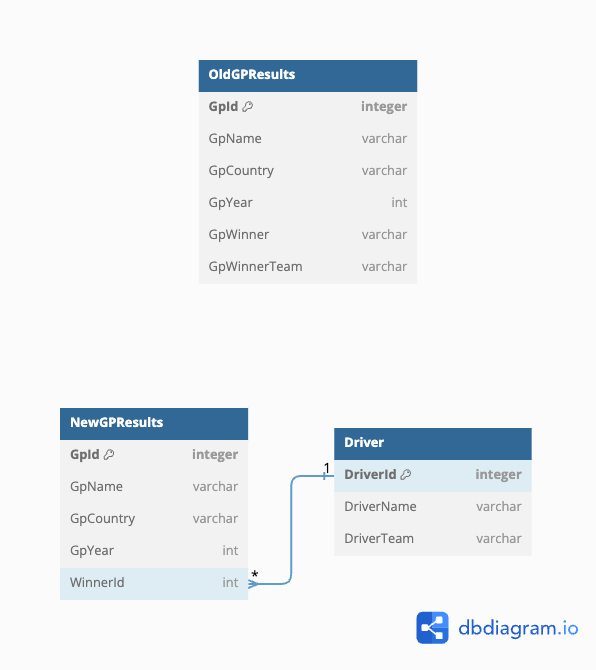
Beyond the 3NF
As I anticipated in the beginning, normal forms go way beyond the 3NF, but they’re mostly of academic interest and there’s little to none interest in normal database development to keep this order of normalization. But for the sake of curiosity, let’s anyway have a look to what we can find beyond the 3NF.
Boyce-Codd Normalization Form
BCNF is a stricter version of 3NF where every determinant is a candidate key. It ensures that functional dependencies are resolved more rigorously, even in complex scenarios.
Fourth and Fifth Normalization Forms
4th Normalization Form deals with multi-valued dependencies while the 5th Normalization Forms define a standardized way to work with joined tables.
Conclusion
When I first entered the world of database management, I was completely new to best practices, including the intricate world of normalization forms. Fortunately, a supportive work environment allowed me to dig into these concepts and encouraged me to share my findings. For people who know my background, will be no surprise the fact that most IT best practices and enterprise-level common solutions are still somehow obscure. Surprisingly to me, this is also the case for many young developers grinding their way into the dynamic world of startups. Unlike many other sectors, though, startups are renowned for their knowledge-sharing spirit and flat structure; I was, therefore, able to contribute significantly to my team’s efforts in better designing database schema changes. This journey has not only enhanced my skills but also enabled me to support my colleagues in creating optimized and high-performing RDBM environments.
Bibliography and Additional Resources
I collect here below some interesting resources that I stumbled upon
- Refactoring Database: Evolutionary Databases Design; like the code that we use, also databases need to be refactored and adapted to the ever-changing specs and requirements. Unlike the code base, though, databases need to be handled with extra care, especially in the case the database is shared across different actors and services. This book provides a practical and concrete set of strategies to apply in the presence of different refactoring needs.
- Database Internals: A Deep Dive into How Distributed Data Systems Work; The book is divided into two parts; The first part deals with B*-trees, LSM-trees, differences between locks and latches, memory VS disk optimizations, rebalancing, concurrency models for transactions, etc. The second part is more about distributed systems (Paxos algorithms, replication, byzantine fault, etc). All in all an essential vademecum for anyone who wants a refresher on the pros and cons of the enormous plethora of different solutions that are available out there when talking about databases.
- Software Architecture: the hard parts. A comprehensive overview of best practices and ideas to apply when there are no design patterns that match our use case. Moving from a monolithic to a microservice structure, while refactoring team structure and database usage is one of the most difficult steps to take in modern IT. This book is an essential vademecum to survive this challenging process.
- This beautiful YouTube video introduces all the normalization forms.